

For organizations considering dipping their toes into the Machine Learning (ML) waters, what has changed since ML and Big Data first emerged, and how can ML change your application development? What use cases are best suited for ML? How can I identify scenarios not only where ML can be used, but in fact should be used?
Background
A few years ago, I was heading into learning all about “Big Data”. That meant Hadoop, Spark, Kafka and new tools emerging from the university castes. At the time, the courses I took were a part of a collection of skills known as data science. It was an interesting scientific journey into a new field that was just emerging.
My attempts to take the skills that I learned and apply them in a real-world, budgeted project was considerably less exciting. While the big consulting firms with big budgets were blogging about their various “Big Data” initiatives, smaller, real-world “attainable” projects stalled out.
In 2015 Gartner published its famous Hype Cycle that put Machine learning at the peak of expectations.
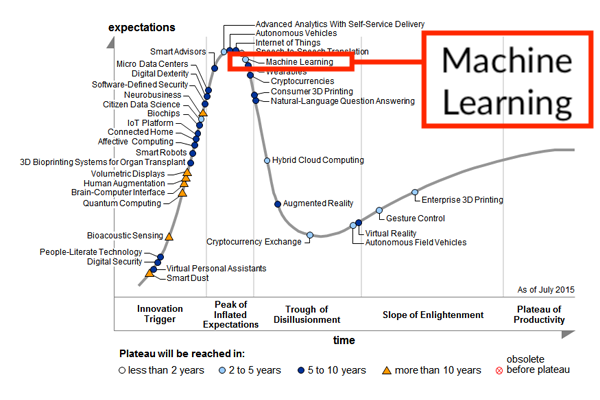
In my experience, Gartner was bang on, and the reality of those hyped projects largely played out as predicted. The thing is, we don’t hear about Big Data, or Machine Learning much anymore. Why is that?
Well, there are a couple of reasons and all of them come back to a conversation that I had while taking that Big Data course. A fellow student and I were discussing what the next steps are for Big Data and how to sell it to customers. We concluded that you don’t sell Big Data, you sell its value through practical applications. In other words, the CHRO or CFO don’t care about the technology that powers translation or Siri or Alexa or spam filtering. They just don’t want spam in their mailbox. And if ML can do a better job than existing spam filtering algorithms, both cheaper and faster and more accurate, then the market will evolve to use ML as part of the product.
Big data and Machine Learning have dropped off the hype curve, not because they have disappeared, in fact, they are more powerful and transformative than ever. But today, they are now hidden within real products that are so commonplace, we take them for granted. The facial recognition algorithm in your phone is powered by ML, and it’s amazing, yet super boring: it unlocks your phone.
“That’s not normal”
 At Dispatch, we build data integration and workflow automation solutions for large, complex enterprises. Most of the solutions we build are for mission-critical business processes that need to be resilient and adaptive. We work with massive amounts of data, but instead of relatively static big data “lakes”, we work with rivers of data that flow in near real-time between applications. This data is transient, and time-domain bound. ML can provide immense value for our clients when applied correctly. One of the biggest tells for considering ML in requirements gathering and feature evaluation is when a customer can describe a situation in terms of normalcy.
At Dispatch, we build data integration and workflow automation solutions for large, complex enterprises. Most of the solutions we build are for mission-critical business processes that need to be resilient and adaptive. We work with massive amounts of data, but instead of relatively static big data “lakes”, we work with rivers of data that flow in near real-time between applications. This data is transient, and time-domain bound. ML can provide immense value for our clients when applied correctly. One of the biggest tells for considering ML in requirements gathering and feature evaluation is when a customer can describe a situation in terms of normalcy.
Normalcy is a broad and largely misunderstood term, but it’s something that everyone can feel and describe.
During a global pandemic we know that things aren’t normal, we have deviated from historic behavior. We must stand 6 feet apart, wear masks, don’t go to movies.
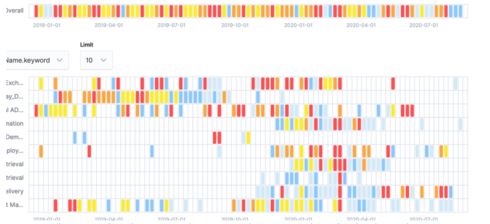
We can also see normalcy in the data we work with day to day: we can detect obvious distortions in standard expectations. In the picture above, the gold bottle is obviously abnormal, it stands out visually. In the graph below, which is a depiction of data flow across an organization, the red bars are obviously abnormal:

It’s easy to see that the graph is “normally” green and a block of red distinguishes an area where failures are taking place. And while the occasional failure is normal (note: “normal” does not mean “desirable”), a block of failures is not.
This is a great application of Machine Learning because the machine or algorithm can be trained to understand “normal”.
Traditionally, business systems have asked users to describe the boundaries of normalcy manually which leads to very poor and inflexible descriptions of abnormalities. Think about the sentence: “It has rained less recently”. The questions that come to mind are, less than what? And for where? And over what time span?
Similarly, for computer systems, we have traditionally had to set the boundaries of normal for the computer to detect abnormal situations. An easy one is, if the CPU spikes for > 5 minutes, send an alert. A much harder anomaly to detect is when the payroll file settlement balance is a standard deviation different than normal for the past 15 months. Setting an arbitrary alert level at 1.5 million dollars for a two-week payroll won’t work because of the natural and normal expansions and contractions of the workforce over time. Instead, by capturing the organizational context for data, ML algorithms can detect statistically significant differences from the normal ebb and flow of values – even when those differences are small. In fact, ML really shines when the differences are not obvious (to the naked eye), but none-the-less very real and actionable.
When the user community begins to express their requirements in terms of normalcy, a systems architect should pick up on these signals that ML may in fact be the right tool for the problem at hand. And if the user community expresses that the cost of “non-normal” behavior is high, ML might become invaluable.
An Evolution
 Going back to the beginning, ML projects have fallen off the radar because they were a solution in search of a problem. Any CIO suggesting that an organization must start an ML project because “it’s everywhere” is starting from the wrong end of the requirements lifecycle. Instead, in the expression of business requirements, the architect must work with the user community to evaluate the “art of the possible” that now includes ML as one of the tools in the toolbox.
Going back to the beginning, ML projects have fallen off the radar because they were a solution in search of a problem. Any CIO suggesting that an organization must start an ML project because “it’s everywhere” is starting from the wrong end of the requirements lifecycle. Instead, in the expression of business requirements, the architect must work with the user community to evaluate the “art of the possible” that now includes ML as one of the tools in the toolbox.
The major PaaS vendors have now baked ML tools behind “easy to use” APIs and user interfaces. For example, with ElasticSearch 7.x, ML tools are as close as a few clicks away from detecting integration run time anomalies.
All of the major platform vendors have robust and “easy to use” ML tools. These vendors provide targeted prebuilt algorithms that can solve existing common use cases; for example Voice to Text or Image Recognition. They also provide general-purpose tools and infrastructure to craft the algorithms that are custom-built for specific edge cases.
The Forward-Looking Organization
With the framework outlined above, Dispatch is working with organizations that are moving up the value chain. With the (now accelerated) digital transformation underway, IT has become an enabler, supporting line of business departments to explore their own transformation. Where HR might have previously dealt with pdf’s or scans of documents to capture compliance and risk management processes, new use cases are emerging that leverages the power of ML and AI tools to transcribe, search, identify and manage high-risk situations – to identify the “not normal” in a sea of document exchanges between employees, companies and trading partners.
We are working with teams that are focused on outcomes that let us “automate the work, but not the worker”. By leveraging workflow data management tools such as Workato, we can help your organization tap into productivity potentials that were previously unreachable.
Contact us today to help us get your organization to a “new normal”.
References:
Normality: Part descriptive, part prescriptive
Statistical Literacy
Deep Learning’s ‘Permanent Peak’ On Gartner’s Hype Cycle
About Dispatch Integration:
Dispatch Integration is a software development and professional services firm that develops, delivers, and manages advanced data integration and workflow automation solutions. We exist to help organizations effectively deal with the complex and ever-changing need to integrate data and optimize end to end workflows between cloud-based, mission-critical applications.
Read More from Dispatch Integration:
Our Approach to Hypercare Using Sentinel
Synchronizing Equity Compensation Data between Workday and Solium (Now Shareworks)
Automating Customer Support for Efficiency, Quality and Scalability

Gavin Hay is the co-founder, President, and CTO of Dispatch Integration with experience leading high performing cross-functional teams. He has over 20 years of experience as a systems architect in the HR and Payroll industry and has a deep understanding of the full stack technology infrastructure required to deliver exceptional software integrations.